人工智能 2021-02-02 12128
答案是深度学习既是机器学习的子集又不是机器学习的子集。
机器学习属于计算机科学,是使用统计学或数学技术从利用观察到的数据构建模型或系统,而不是用户输入定义该数据模型的特定指令集。
这个名字看起来比较高大上,但有时候基本的机器学习跟线性回归一样简单。复杂一点的例子是用户邮箱中的垃圾邮件检测器,虽然用户从来不对每种类型的电子邮件发出指示,但垃圾邮件检测器会“学习”哪些电子邮件是垃圾邮件。
笼统地说,这些算法最常用于从原始数据中提取精确特征集。特征可以非常简单,例如图像的像素值、信号的时间值,也可以复杂,例如文本的词袋特征表示。大多数已知的机器学习算法跟表示数据的特征一样好用。正确的特征识别是准确代表所有数据的状态的关键一步。
正确的特征提取器本身就有很高的科技含量。大多数数据特征提取器在功能和实用性上都非常特殊。例如:进行面部检测所需的特征提取器要具备能够正确地表示面部组成、抵抗空间像差等功能包括。每种类型的数据和任务都有其的特征提取类别,例如语音识别和图像识别。
然后可以使用这些特征提取器来提取给定样本的正确数据特征,并将该信息传递给分类器或预测器。
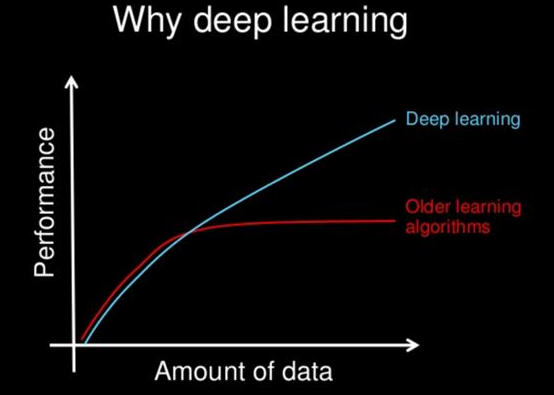
深度学习是广义的机器学习的一部分,它试图学习给定数据的高级特征。因此,深度学习所解决的问题是减少为每种类型的数据(语音、图像等)制作新的特征提取器的个数。
再举个例子,给深度学习分配识别图像的任务,深度学习算法会试着学习诸如双眼之间的距离、鼻子的长度等特征,然后用这些信息进行分类、预测等任务。这也是深度学习算法比之前的“浅度学习算法”更为先进之处。
如吴恩达教授所说,深度学习关注的是学习的原始目标,是人工智能的理想算法。
简而言之:
如果你写下如下的公式: F(1,2,3.......,100) = 5050 如果把这个公式输入到机器学习算法,那么机器学习算法就会像个孩子一样立即把它理解为等号右边是等号左边所有数字的和。再给机器学习一串新的数字F(1,2,3 .......,500),机器学习就会把括号里面的所有500个数字累加起来求和。
但深度学习算法会像卡尔·弗雷德里希·高斯一样,把这串数字倒过来,就会发现两列数字的第i个数字之和始终是相同的,最后再进行总体求和。